This post will have all the useful links and my notes to prepare for AWS Certified AI Practitioner Exam. (AIF-C01).

How I prepared for AWS Certified AI Practitioner
To begin with, following are two important AWS exam resources that you must go through thoroughly.
1. Exam review guide
2. The 4-step plan
Both of the resources are provided by AWS themselves and i highly recommend going through them once. This will give you a very good overview of what to expect in the exam, why are you preparing and how to prepare for it.
After going through the two links above, I enrolled myself in the course: “Fundamentals Of Machine Learning and Artificial Intelligence”, which was provided by AWS. It will ask you to sign up and prepare a builder id, but it is free. So, make use of it, while it lasts. Link to the course: https://explore.skillbuilder.aws/learn/public/learning_plan/view/2193/standard-exam-prep-plan-aws-certified-ai-practitioner-aif-c01
Domain 1 Fundamentals of AI and ML
In this section, AWS has explained conceptually, what does AI/ML, Deep Learning, Gen AI actually means and how does it all fits together. It also goes through select AWS services which you will use when using with AI/ML related frameworks in your day to day.
1.2 -> Common uses cases for AI, both when to use and when not to use, also what services are provided by AWS
1.3 -> ML dev lifecycle, ML pipelines, AWS services used, Evaluating model against performance and business use cases
Domain 1.1 – Explain the basic concepts of AI and it’s subcomponents ML and DL. Describe how ML models work or developed
In this module, the objective is to learn the basic concepts behind AI, ML, DL and GenAI. To begin with, just make sure you remember this image below as you proceed through this section. This lays the foundation for this and the following sections.
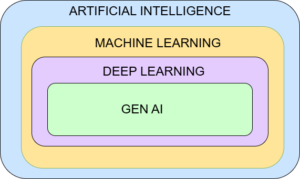
What is Artificial Intelligence (AI)?
In very simple terms, conceptually, AI is all about developing intelligent systems which performs the tasks usually carried out by humans.
As you can see from the image above, it is the superset of all the related concepts that we hear about, such as Machine Learning, Deep Learning and Gen AI.
Goal is to create self learning system that derives meaning from data.
It is good at handling monotonous tasks and thus freeing up employees and increasing business efficiency.
It is very useful and powerful when it comes to finding patterns in data and forecasting trends, thus business makes smart decision
Theoretically, or book definition: Field of computer science dedicated to solving problems associated with human intelligence, such as learning, creation and image recognition. AI can respond meaningfully when you ask questions and can even create original content, such as text and images
AI Components:
1. Data Layer
AI needs vast amount of data. Data is at the heart/core of it. At this layer we collect the data.
2. ML Framework and Algorithm layer
It is important to understand the use cases, requirements and framework that can solve the problem in hand.
3. Model layer
Once we have the data and problem statement well understood, we implement a model and train it using the data collected above.
4. Application Layer
Model generated above is what is the end product. This layer is concerned about how to serve the model, and its capabilities for the users
Machine Learning (ML)
Conceptually: “We’ve seen a lot of similar things before, and we can classify them” . ML is a type of AI that uses data to improve computer performance. No explicit programming of rules, its all data. Data is leveraged to improve computer performance on a set of task.
Theoretically: Branch of AI and CS that focuses on use of data and algorithms, to imitate the way human learns, it gradually improves it’s accuracy to build computer systems that learn from data
Trained by using large datasets that identify patterns and make prediction.
Computer systems process large quantity of historical data and identify data patterns
To train the algorithm to produce the output we expect, we input the known data to the algorithm which consists of features.
We train the algorithm by giving it more data as input.
It’s task is to find the correlation between the given data input features and expected output, if available
Adjustments are made to the model by adjusting internal param value, until the model reliably produces expected output.
Few questions I am sure you must be looking answers for:
1. What is a Classification? -> It is like a rule to classify data
2. What is a feature? -> Think of it as attributes, properties, just like columns in a table.
3. What is inference> -> Trained model is then able to make accurate prediction and able to produce output on new data as well.
Types of data:
Structured data
Structured – rows and columns, text files like csv, columns are features,
Data is organized in a structured format, often in rows and columns
1. Tabular Data – arranged in rows and columns representing features
2. Time Series Data – data points collected or recorded at successive points in time
S3 is primary source of training data
Semi-structured:
Unlike data in a table, it can have attributes. text file which has JSON or XML. features are represented as key value pair
DynamoDB, DocumentDB with mongodb can be used for these
Unstructured
No data model and can’t be stored in table. stored as objects in object storage system such as s3.
Features are derived using tokenization, breaking up individual words or phrases
doesn’t follow a specific structure and is often text-heavy or multimedia content. Text data, image data
Time-series data
Important for training model that need to predict future trends.
Each is stored with timestamp
Training process produces model artifacts, which typically consists of trained parameters and model definition that describes how to compute inferences and other metadata.
Model artifacts which are typically stored in S3 are packaged together with inference code, to make a deployable model
Inference code is the software that implements the model, by reading the artifacts
Q.) Two options of hosting the model
1. Endpoint is always available, to accept inference request in real time. Low latency and high throughput. Persistent endpoint.
2. Batch job is performing inference. Offline, large datasets and infrequent use.
ML Styles that can be used, depending on the expected output and input type
Supervised Learning – regression – classification
Binary – probability that something is true
Multiclass – prediction of class
You train your model with data that is pre-labeled.
e.g. you can train your model with pictures labeled as fish, in the same dataset you add non-fish labels. The model will look at pixels and recognizing patterns and clusters. Internal parameters are adjusted during the training. It continues until the model is successfully identifying the images as fish that are labeled as fish. Model here is generating the probability that the image is a fish.
Challenge is in labeling the data
Amazon mechanical turk – provides access to large pool of labor that can label your data.
When your target values is mathematically continuous, you have regression problem
regression estimates target variable based on one or more other variable or attributes that are correlated with it.
e.g. predict one value based off of another
Simple linear regression, multiple linear regression or logistic regression
Logistic regression – predicts the probability of an event occurring. Value between 0 and 1.
Unsupervised learning
It has unlabeled Data. It has features but is not labeled. They can spot patterns, group the data into clusters and split the data into certain number of groups.
Clustering – define features, similarity function, number of clusters
Anomaly detection
Useful for use cases such as pattern recognition, anomaly detection.
Clustering: Identifying different types of network traffic to predict potential security incident. Commonly used for anomaly detection.
Reinforcement Learning
ML method that is focused on autonomous decision making by an agent. The agent takes action within an environment to achieve specific goal. The model learns through trial and error and training does not require labeling input.
Action that agents take which are making it closer to achieving goal are rewarded, to encourage learning during training.
Amazon provides deepracer that you can teach to drive on a racecar. The car is the agent and track is the environment. Action is the car moving forward. Trial and Error. Maximize rewards. Has a pre-determined end goal.
Machine Learning Techniques and Use Cases
Supervised Learning:
Algos are trained on labeled data.
Goal is to learn a mapping function that can predict the output for new, unseen input data.
Regression:
Used to predict a numeric value based on input data
The output variable is continuous, meaning it can take any value within a range
Use cases: used when the goal is to predict a quantity or real value
e.g. predicting house prices, stock price prediction, weather forecasting
Classification:
Used to predict the categorical label of input data
The output variable is discrete, which means it falls into a specific category or class
Use Cases: scenarios where decisions or predictions need to be made between distinct categories
e.g. Binary Classification – classify email as spam or not spam
Multiclass classification – classify animals in zoo as mammal, bird or reptile
Unsupervised Learning:
Algos learn from unlabeled data
Goal is to discover inherent patterns, structures or relationship with input data
Reinforcement Learning:
The machine is given only a performance score as guidance and semi-supervised learning, where only a portion of training data is labeled. Feedback is provided in the form of rewards or penalties for its actions and the machine learns from this feedback to improve it decision-making over time.
Supervised Learning Use Case
The supervisor is labeled training data. Essentially, this type of algorithm uses training data to help determine the patterns and relationships between the inputs and outputs.
The model learns by identifying patterns in data that’s already labeled.
Types of supervised ML
Classification:
supervised learning technique used to assign labels or categories to new, unseen data instances based on a trained model. The model is trained on a labeled dataset, where each instance is already assigned to a known class or category. The goal of classification is to learn patterns from the training data and use them to predict the class or category for new unlabeled data instances.
Use cases include the following:
Diagnostics
Fraud detection
Image classification
Customer retention
Regression:
supervised learning technique used for predicting continuous or numerical values based on one or more input variable. It is used to model the relationship between a dependent variable (the value to be predicted) and one or more independent variables (the features or inputs used for prediction).
Use cases include the following:
Population growth prediction
Advertising popularity prediction
Weather forecasting
Market forecasting
Estimating life expectancy
Unsupervised Learning Use Case
The algorithm tries to discover hidden patterns or structures within the data without any prior information or guidance. the machine has to uncover and create the labels itself. These models use the data they’re presented with to detect emerging properties of the entire dataset and then construct patterns.
Types of Unsupervised Learning:
Clustering:
This kind of algorithm groups data into different clusters based on similar features or distances between the data point to better understand the attributes of a specific cluster.
For example, by analyzing customer purchasing habits, an unsupervised algorithm can identify a company as being large or small.
Use cases include the following:
Recommended systems
Customer segmentation
Targeted marketing
Dimensionality Reduction:
Unsupervised learning technique used to reduce the number of features or dimensions in a dataset while preserving the most important information or patterns.
Use cases include the following:
- Big data visualization
- Meaningful compression
- Structure discovery
- Feature elicitation
Self-Supervised learning
Have a model generate pseudo-labels for its own data without having humans label any data first.
We expect data to be labeled by itself
Create “pre-text tasks” to have the model solve simple tasks and learn the patterns in the dataset.
It teaches our model to create a representation of our dataset
Now, we have a model trained that can solve our end goal: “downstream tasks”
Reinforcement Learning Use case
This one continuously improves its model by mining feedback from previous iterations. In reinforcement learning, an agent continuously learns through trial and error as it interacts in an environment. Reinforcement learning is broadly useful when the reward of a desired outcome is known, but the path to achieving it isn’t—and that path requires a lot of trial and error to discover.
Type of ML where an agent learns to make decisions by performing actions in an environment to maximize cumulative rewards
Key Concepts:
Agent – the learner or decision maker
Environment – the external system the agent interacts with
Action – the choices made by the agent
Reward – the feedback from the environment based on the agent’s feedback
State – the current situation of the environment
Policy – the strategy the agent uses to determine action based on the state
RLHF = Reinforcement Learning from Human Feedback
Use human feedback to help ML models to self-learn more efficiently
incorporates human feedback in the reward function, to be more aligned with human goals, wants and needs
RLHF is used throughout GenAI applications including LLM models
significantly enhances model performance
1. Data collection
2. Supervised fine-tuning of a language model
3. Build a separate reward model
4. Optimize the language model with the reward-based model
Troubleshooting model performance:
1. Overfitting
When the model performs better on training data than on new data, it is called overfitting.
Solution is to train it with data that is more diverse.
If you also train your data for long time, it will start to emphasize on unimportant feature called noise.
2.Underfitting
Occurs when a model can not determine a meaningful relationship between the input and output data.
Gives inaccurate results even for training data.
Happens when training time is less or not trained with large enough dataset.
3. Bias and fairness
When there are disparities in the performance of the model across different groups. The result is in the favor of a particular class.
diversity of training data should be there. Quality of model depends on underlying data quantity and quality.
Weight given to features could also be another cause of model showing bias.
data should be fair, not discriminating against one. Data should be inspected and evaluated for such things.
Deep Learning
Inspired by human brains, using layers of neural networks to process information.
Consists of nodes. Input layer then multiple hidden layers and then output layer.
Each node in the network autonomously assigns a weight to each feature. Information flows in the network in the forward direction.
During training, predicted and actual output is compared and weight of nodes is adjusted to minimize the error.
recognizing human speech, objects and images
DL -> Similar to how our brain is wired. It used the concept of neurons and synapses to train a model.
Able to process more complex patterns in the data than traditional ML
because there is more than one layer of learning
e.g. Computer Vision, NLP
Large amount of input data, requires GPU
Gen AI -> generate new data based on patterns and structure learned from training data. Multi purpose foundation models backed by neural networks. Which is why it is a subset of Deep Learning.
Gen AI
Accomplished using Deep learning foundation models that are pre-trained on extremely large datasets.
Uses transformer neural networks which change an input sequence, known as prompt, into an output sequence which is the response to your prompt. It processes the sequence of inputs in parallel, which speeds up training and also allows big datasets to be used.
Excel at understanding human language. Used for text classification, generation, translation and code generation.
Transformer Model (LLM)
Able to process a sentence as a while, instead of word by word
Faster and more efficient text processing
Powerful models that can understand and generate human-like text
Trained on vast amount of text data from the internet, books and other sources
Generative AI is a branch of AI which focused on generating new content, such as Text, Audio, Image and even code from existing data. It uses the pattern and relationships from vast amount of training data and use that knowledge to generate entirely new content. Whereas, AI and ML were simply analyzing and interpreting data.
Consider AI/ML for..
Increasing business efficiency – automating tasks, streamline self service process.
Solving complex problems – fraud detection, waste reduction
Making better decisions – forecasting future actions, getting answers fast
When not to choose AI/ML
Costs outweigh the benefits
models cannot meet the interpretability requirements, consider a rules based system
systems must be deterministic rather than probilistic
What can AI do
1. Recognize patterns and make predictions
Using a technique called regression analysis, an AI model can process historical data, also known as time series data and predict future values
Predictions that AI make are called inferences. Inference is basically an educated guess
2. Detect anomalies
3. Detect defects by using computer vision
4. Translation, from one language to another
5 NLP
6. Create content (GenAI)
Introduction
ML Terms you need to know
GPT – Generative Pre-trained Transformer
Generate human text or computer code, based on input prompt
BERT – bidirectional Encoder Representations from Transformers. Reads text in two directions, good for translation
RNN – Recurrent Neural Network, meant for sequential data such as time-series or text, useful in speech recognition, time-series prediction
ResNet – Residual Network – used for image recognition tasks, object detection, facial recognition
SVM – Support Vector Machine – ML algo for classification and regression
WaveNet – model to generate raw audio waveform, used in speech synthesis
GAN – generative Adversial Network – models used to generate systhetic data such as images, video or sounds that resemble training data
XGBoost – Extreme Gradient Boosting – an implementation of gradient bosting
Machine Learning Fundamentals
Collect data, train the model on prepared data and evaluate its performance through testing and iteration.
Train Data -> ML Algorithm -> Model
AWS Infrastructure and Technologies
ML Framework
Amazon Sagemaker –
Plays a crucial role in the development and deployment of ML models.
Offers tools to build, train, deploy and run LLMs and your own custom models.
Provides tools and infra to accelerate your dev and deployment lifecycle.
AI/ML Services
Specialized services tailored for different use cases. This layer includes a wide range of services that provide developers with AI/ML capabilities without requiring extensive infrastructure management or specialized expertise.
Text and Document:
Amazon Comprehend, Amazon Translate, Amazon Textract
Amazon Comprehend uses ML and natural language processing (NLP) to help you uncover the insights and relationships in your unstructured data. This service performs the following functions:
- Identifies the language of the text
- Extracts key phrases, places, people, brands, or events
- Understands how positive or negative the text is
- Analyzes text using tokenization and parts of speech
- And automatically organizes a collection of text files by topic
Use Cases:
Analyze customer interactions to find what leads to positive or negative experience
Create and group articles by topics that comprehend will uncover
Custom Classification – Organize documents into categories that you define
It does NER – Named Entity Recognition – extracts predefined, general-purpose entities like people, places from text.
Custom Entity Recognition – Analyze text for specific terms and noun-based phrase.
Extract terms like policy numbers or phrases that imply a customer escalation, anything specific to your business
Real-time or async analysis
Amazon Translate
Translate between 75 languages
is a neural machine translation service that delivers fast, high-quality, and affordable language translation.
Neural machine translation is a form of language translation automation that uses deep learning models to deliver more accurate and more natural-sounding translation than traditional statistical and rule-based translation algorithms.
With Amazon Translate, you can localize content such as websites and applications for your diverse users, translate large volumes of text for analysis, and efficiently implement cross-lingual communication between users.
Amazon Textract is a service that automatically extracts text and data from scanned documents.
Amazon Textract goes beyond optical character recognition (OCR) to also identify the contents of fields in forms and information stored in tables.
Vision:
Amazon Rekognition
Amazon Rekognition facilitates adding image and video analysis to your applications.
It uses proven, highly scalable, deep learning technology that requires no ML expertise to use.
With Amazon Rekognition, you can identify objects, people, text, scenes, and activities in images and videos, and even detect inappropriate content.
Amazon Rekognition also provides highly accurate facial analysis and facial search capabilities.
You can use it to detect, analyze, and compare faces for a wide variety of user verification, people counting, and public safety use cases.
Custom Labels – e.g. find your logo in social media posts, identify your products on stores shelves
Label your training images and upload them to amazon rekognition, which creates a custom model on your image set. New subsequent images will be categorized the custom way you have defined.
Content moderation. Integrated with Amazon Augmented AI for human review. as well as custom moderation adaptors
Search:
Amazon Kendra
Intelligent document search
Amazon Kendra is an intelligent search service powered by ML.
Amazon Kendra reimagines enterprise search for your websites and applications.
Your employees and customers can conveniently find the content that they are looking for, even when it’s scattered across multiple locations and content repositories within your organization.
Chatbots:
Amazon Lex
Amazon Lex is a fully managed AI service to design, build, test, and deploy conversational interfaces into any application using voice and text. Amazon Lex provides the advanced deep learning functionalities of automatic speech recognition (ASR) for converting speech to text, and natural language understanding (NLU) to recognize the intent of the text.
This permits you to build applications with highly engaging user experiences and lifelike conversational interactions, and create new categories of products.
With Amazon Lex, the same deep learning technologies that power Amazon Alexa are now available to any developer.
You can efficiently build sophisticated, natural-language conversational bots and voice-enabled interactive voice response (IVR) systems.
Integration with AWS Lambda, Connect, Comprehend, Kendra
Intent represents the action that user wants to accomplish
Amazon Forecast
Predicts future points in time-series data
Fully managed service that uses ML to deliver highly accurate forecasts
e.g. predict future sales of raincoat
Speech:
Amazon Polly, Amazon Transcribe
Transcribe – speech to text
Polly – Text to speech
Amazon Polly is a service that turns text into lifelike speech.
Amazon Polly lets you create applications that talk, so you can build entirely new categories of speech-enabled products.
Amazon Polly is an AI service that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. Amazon Polly includes a wide selection of lifelike voices spread across dozens of languages, so you can select the ideal voice and build speech-enabled applications that work in many different countries.
Polly – Advanced features:
1. Lexicons – define how to read certain specific pieces of text
2. SSML – Speech Synthesis Markup Language
3. Voice Engine
4. Speech mark- encode where a sentence/word starts or ends in audio
Amazon Transcribe is an automatic speech recognition (ASR) service for automatically converting speech to text.
The service can transcribe audio files stored in common formats, like WAV and MP3, with time stamps for every word so that you can quickly locate the audio in the original source by searching for the text.
You can also send a live audio stream to Amazon Transcribe and receive a stream of transcripts in real time.
Amazon Transcribe is designed to handle a wide range of speech and acoustic characteristics, including variations in volume, pitch, and speaking rate. Automatically removes PII using redaction. Supports automatic language identification for multi-lingual audio
We can improve accuracy by allowing Transcribe to capture domain-specific or non-standard terms (e.g. technical words, acronyms, jargon…). Custom vocabularies for words and custom language model for context
Customers can use Amazon Transcribe for a variety of business applications, including the following:
- Transcription of voice-based customer service calls
- Generation of subtitles on audio and video content
- Conducting (text based) content analysis on audio and video content
- Toxicity detection capability
- Amazon transcribe Medical automatically convert medical-related speech to text and is HIPAA compliant)
Recommendation:
Amazon Personalize
Personalized product recommendations
Amazon Personalize is an ML service that developers can use to create individualized recommendations for customers who use their applications.
With Amazon Personalize, you provide an activity stream from your application (page views, signups, purchases, and so forth).
You also provide an inventory of the items that you want to recommend, such as articles, products, videos, or music.
You can choose to provide Amazon Personalize with additional demographic information from your users, such as age or geographic location.
Amazon Personalize processes and examines the data, identifies what is meaningful, selects the right algorithms, and trains and optimizes a personalization model that is customized for your data.
Misc:
AWS DeepRacer
AWS DeepRacer is a 1/18th scale race car that gives you an interesting and fun way to get started with reinforcement learning (RL). RL is an advanced ML technique that takes a very different approach to training models than other ML methods. Its superpower is that it learns very complex behaviors without requiring any labeled training data, and it can make short-term decisions while optimizing for a longer-term goal.
Amazon Fraud detector
Detects fraud and fraudulent activities
Amazon Mechanical Turk
Crowdsourcing marketplace to perform simple human tasks
Distributed virtual workforce
e.g. you have a dataset of 1million images and you want to labels these images… you distribute these tasks on Turk and human will label them. You give them the reward for it afterwards.
ML Development Lifecycle
Identify business goal
Frame ML Problem
Collect data
Pre-process data
Engineering features
Train, Tune, Evaluate
Deploy
Monitor
AWS Glue – cloud optimized ETL service, contains its own data catalog, built in transformations
AWS Glue DataBrew – Visualize and data preparation, data quality rules
SageMaker GroundTruth – does labeling for you as well as give it to humans, like your employees or AWS or vendors.
Amazon’s hardware for AI
1. GPU-based EC2 instances (P3, P4, P5…)
2. AWS Trainium
ML Chip built to perform DL on 100B+ parameter model
Trn1 instance has for example 1 i trainium accelerators
50% cost reduction when training a model
3. AWS Inferentia
ML chip build to deliver inference at high performance and low cost
inf1 and inf2 instances are powered by AWS Inferentia
Up to 4x throughput and 70% cost reduction
Trn and Inf have lowest environment footprint
Generative AI Layer: Services and tools which unlocks the power of FMs.
Amazon Sagemaker Jumpstart,
Provides pre-trained models, foundation models, computer vision, NLP
Fine-tune with your data
Deploy using sagemaker
SageMaker JumpStart helps you quickly get started with ML. To facilitate getting started, SageMaker JumpStart provides a set of solutions for the most common use cases, which can be readily deployed. The solutions are fully customizable and showcase the use of AWS CloudFormation templates and reference architectures so that you can accelerate your ML journey. SageMaker JumpStart also supports one-click deployment and fine-tuning of more than 150 popular open-source models such as natural language processing, object detection, and image classification models.
Amazon Augmented AI
Human oversight of ML predictions in production.
It could be your employees or AWS employees or vendors
Amazon Bedrock – Lets us use and customize FMs
Amazon Bedrock is a fully managed service that makes FMs from Amazon and leading AI startups available through an API. With the Amazon Bedrock serverless experience, you can quickly get started, experiment with FMs, privately customize them with your own data, and seamlessly integrate and deploy FMs into your AWS applications.
Amazon Q, Amazon Q Developer
Amazon Q can help you get fast, relevant answers to pressing questions, solve problems, generate content, and take actions using the data and expertise found in your company’s information repositories, code, and enterprise systems. When you chat with Amazon Q, it provides immediate, relevant information and advice to help streamline tasks, speed decision-making, and help spark creativity and innovation.
Designed to improve developer productivity, Amazon Q Developer provides ML–powered code recommendations to accelerate development of C#, Java, JavaScript, Python, and TypeScript applications. The service integrates with multiple integrated development environments (IDEs) and helps developers write code faster by generating entire functions and logical blocks of code—often consisting of more than 10–15 lines of code.
Why use these specialized services
1. pre-trained ML services
2. Responsiveness and Available
3. Redundancy and Regional coverage
4. Performance
5. Token-based pricing
6. Provisioned throughput
Cost Consideration
Cost trade-offs can impact factors such as responsiveness, availability, redundancy, performance, regional coverage, pricing models, throughput, and the ability to use custom models.
- Responsiveness and availability:
highly responsive and available comes with a cost. e.g. multi region deployment - Redundancy and Regional coverage
services can be deployed across multiple Availability Zones or even across multiple AWS Regions. Which again comes with an additional cost - Performance
different compute options (for example, CPU, GPU, and custom hardware accelerators) for generative AI services - Token Based pricing
you pay for the number of tokens (a unit of text or code) generated or processed by the service. - Provisioned throughput
Some AWS generative AI services, like Amazon Polly and Amazon Transcribe, let you provision a specific amount of throughput (for example, audio or text processing capacity) in advance. - Custom models
you can also bring your own custom models or fine-tune existing models. Training and deploying custom models can incur additional costs, depending on the complexity of the model, the training data, and the compute resources required.
Real World Use Cases in AI/ML/Gen AI
These areas include healthcare, finance, marketing, entertainment, and more
What is AI?
a very broad field that encompasses the development of intelligent systems capable of performing tasks that typically require human intelligence, such as perception, reasoning, problem-solving, decision-making, etc.
What is ML?
Subset of AI for understanding and building methods that make it possible for machines to learn. Uses data to improve computer performance on a set of tasks.
What is Deep Learning?
Uses the concept of neurons and sysnapses, similar to how brain is wired
What is Gen AI?
Subset of DL, as it can adapt models built using deep learning, but without retraining or fine tuning
Capable of generating new data based on the patterns and structures learned from training data.
Real-World Use Cases
Media and Entertainment
Content generation – scripts, dialogues
virtual reality – virtual environment
New generation – articles or summaries
Retail
Product review summaries
Pricing optimization
Virtual Try-ons
Store layout optimization
Healthcare
AWS HealthScribe: generate clinical notes by analyzing patient-clinician conversations
Personalize medicine: generate treatment plans based on a patient’s specific genetic makeup
Improve medical imaging: Ai can generate medical images
Life sciences
Drug Discovery
Protein folding prediction: AI can predict the 3D structures of protien based on their amino acid sequence
Synthetic biology: AI can generate designs for synthetic biological systems
Financial services
Fraud detection mechanism
Portfolio management
Debt collection
Manufacturing
Predictive maintenance
Process optimization
Product Design
Material Science
Examples of AI Applications
Computer vision
NLP
Intelligent Document processing (IDP)
Fraud detection
Computer Vision
Field of AI that allows computers to interpret and understand digital images and videos.
DL has revolutionized computer vision by providing powerful techniques for tasks such as image classification, object detection
It is used by following industries:
Autonomous Driving
Healthcare or medical imaging
Public safety and home security: facial recognition
Natural Language Processing
Branch of AI that deals with the interaction between computers and human languages
DL again has made significant strides in it. It can do text classification, sentiment analysis, machine translation
NLP is used by following industries
Insurance: extract policy numbers, and other personal information
Telecommunication: analyze customer text messages and suggest personalized recommendations
Education: Students use Q&A chatbots to address questions
Intelligent Document Processing
extracts and classifies information from unstructured data, generates summaries and provide actionable insights
IDP is used by following industries
Financial services or lending
Legal
Healthcare
Fraud Detection
process of identifying and preventing fraudulent activities or unauthorized behavior with a system, process or transactions
It is used by following industries
Financial services
Retail
Telecommunication
Machine Learning
Subset of AI that focuses on developing algorithms and statistical models so that computer systems can learn from data and make predictions, without being explicitly programmed.
ML models learn patterns from data rather than relying on hard coded rules for instructions. These models are trained on large datasets, and their accuracy and performance improve over time as they process more data.
When AI and ML are appropriate solutions
AI is good choice for following use cases:
Coding the rules is challenging:
Simple, rule based solutions can not solve the tasks.
e.g. Spam filtering. When rules rely on too many factors, have overlaps or need to be finely tuned, it becomes difficult for them to be coded.
Scale of the project is challenging:
e.g., in spam filtering, a human might be able to scan a few hundred, but scanning through millions of emails would be tedious and inefficient.
Generative AI
subset of deep learning. It can adapt models that are built using deep learning without needing to retrain or fine-tune them. Generative AI is capable of generating new data based on the patterns and structures learned from training data. Generative AI can create new content, including conversations, stories, images, videos, music, and code.
Capabilities of Generative AI
It can automate tedious tasks such as data entry and analyze data to identify patterns and trends, which can assist organization in making more informed decisions.
It can automate complex tasks, freeing time for users to focus on more creative work.
Adaptability
IT can adapt to various tasks and domains by learning from data and generating content tailored to specific contexts or requirements.
Responsiveness
It can generate content in real-time, which result in rapid response times and dynamic interactions.
e.g. Chatbots, virtual assistants and other interactive applications
Simplicity
It can simplify complex tasks by automating content creation processes.
e.g. It can generate human-like text, which reduces the time and effort required for content generation.
Creativity and exploration
Generative AI models can generate novel ideas, designs, or solutions by combining and recombining elements in unique ways. This can foster creativity and exploration of new possibilities.
Data efficiency
Some generative AI models can learn from relatively small amounts of data and generate new samples consistent with the training data. This can be useful when data is scarce or difficult to obtain.
Personalization
It can create personalized content tailored to individual preferences or characteristics, which enhances user experiences and engagement.
Scalability
When trained, generative AI models can generate large amounts of content quickly. This makes the models suitable for tasks that require producing content at scale.
Challenges of Generative AI
Regulatory violation, social risks, privacy concerns, potential to make decisions that are unethical or socially irresponsible
Regulatory violations
AI models are trained on sensitive data, thus output can have PII data.
Social risks
Unwanted content that might reflect negatively on your organization
Data security and privacy concerns
privacy laws can be violated due to data shared with the model
Toxicity
Gen AI models can generate content that is offensive or inappropriate
Hallucinations
model generate inaccurate responses that are not consistent with the training data.
Interpretability
Users might misinterpret the model’s output which could lead to incorrect conclusions or decisions
Nondeterminism
The model might generate different outputs for the same input, which can cause problem where reliability is the key.
Factors to consider when choosing the Gen AI model
Choosing the right model is crucial for achieving the desired results.
Key factors to consider when selecting an appropriate Gen AI model:
Model types
Performance requirement
Capabilities
Constraints
Compliance
Performance
Accuracy, reliability of output
Assess the overall performance of the model to evaluate its suitability for a particular task.
You should also test the model against different datasets to ensure reliability.
Finally, monitor its performance over time to ensure it remains consistent.
Constraints
Computational resources: GPU, CPU, memory
Data availability: Size and quality of training data
Deployment requirement: on prem or on cloud
Capabilities
it is important to understand the specific capabilities required for your application before selecting a generative AI model.
It can perform different tasks with varying degrees of output quality and levels of control or customization
Compliance
the model should adhere to relevant regulation guidelines.
Generative AI models can pose moral concerns, including biases, privacy issues, and potential misuse
Cost
Remember to evaluate all expenses related to deployment, maintenance, hardware, software, and other associated costs.
Larger models are usually more precise, but they are expensive and offer few deployment options. smaller models are cheaper and faster, and they offer more deployment alternatives.
Business Metrics for Gen AI
By quantifying the performance, effectiveness, and return on investment (ROI) of AI applications through relevant business metrics, organizations can gain valuable insights into the value delivered
User Satisfaction
Average revenue per user
Cross-domain performance: ability of model to perform effectively across different domains or industries
Conversion rate e.g. convert visitor to paying customer on ecommerce website
Efficiency: model’s efficiency in resource utilization, computation time, and scalability.
Responsible Artificial Intelligence Practices Course
Practices and principals that ensures that AI systems are transparent and trustworthy while mitigating potential risks and negative outcomes.
Lifecycle of an AI app:
Design, Development, Deployment, Monitoring, Evaluation
Traditional AI
traditional AI models performs tasks based on the data you provide.
Each model can perform only one task. And to do that, they need to be trained carefully on the data. As they train, they analyze the data and look for patterns. Then these models make a prediction based on these patterns.
Some examples of traditional AI include recommendation engines, gaming, and voice assistance.
Generative AI
runs on Foundation Models (FMs).
These models are pre-trained on massive amount of data that is beyond your own data.
They can perform multiple tasks
Model generates content, based on user input, usually in the form of text called prompt.
The content it produces, comes from learning patterns and relationships that empower the model to predict the desired outcome.
Some examples of generative AI include chatbots, code generation, and text and image generation.
Responsible AI Challenges
Accuracy of models
AI models generate content or make decision based only on the data they are trained on. If not trained properly, you will get inaccurate results.
Therefore, it is important to address Bias and Variance in your model.
Bias
It means that model is missing important features of the datasets.
It means that data is too basic
Difference between the expected predictions of the model and the true values we are trying to predict
If the difference is narrow, the model has low bias, if wide then it has high bias.
High Bias = underfitted. i.e. model performs poorly on the training data.
Variance
Model’s sensitivity to fluctuations or noise in the training data. Model might consider noise in the data to be important in the output.
When variance is high, model becomes familiar with the training data and make predictions with high accuracy.
However, when you introduce new data to the model, the model’s accuracy drops. This is because new data can have different features that the model is not trained on.
Overfitting = model performs well on the training data but does not perform well on the evaluation data. This is because the model is memorizing the data it has seen and is unable to generalize to unseen examples.
Bias-Variance Trade-off
Right balance between bias and variance
Low bias and low variance
Captures enough features of the data without capturing noise.
HB, LV = Underfitting
LB, LV = Balanced
HB, HV =
LB, HV = Overfitting
Techniques for overcome Bias and Variance errors:
Cross Validation
Train several ML models on subsets of the available input data and evaluate them on complimentary subset of the data.
Useful to detect overfitting.
Increase Data
Add more data samples to increase the learning scope
Regularization
penalizes extreme weight values to help prevent linear models overfitting training data examples.
Simpler Models
Use simpler models to help with overfitting. If model is underfitting, model might be too simple.
Dimension Reduction
unsupervised machine learning algorithm that attempts to reduce the dimentionality within a dataset which still retaining as much info as possible.
End training Early
So that model does not memorize the data
Model Evaluation Metrics
Confusion matrix is used to summarize a classification model when it is evaluated against task data.
Binary Classification:
True Positive, false negative,false positive, true negative
Precision = TP/ (TP + FP)
Measures how well an algorithm predicts TP out of all the positives that it identifies
Recall = TP/(TP + FN)
Minimize false negative. We don’t want to miss someone who has a disease and we say he don’t
F1 = 2*precision*recall/pr + re
Accuracy = (TP + TN)/Total , where total = TP, FP, TN, FN
Value between 0 and 1, %age of correct. Not good when dataset is imbalanced.
- Precision – Best when false positives are costly
- Recall – Best when false negatives are costly
- F1 Score – Best when you want a balance between precision and recall, especially in imbalanced datasets
- Accuracy – best for balanced datasets
MSE,MAE, MAPE, RMSE, R2 are used for evaluating models that predict a continuous value (i.e. Regressions) –
MAE, MAPE, RMSE – measure the error: how accurate the model is
R2 – measure the variance
Challenges of Gen AI
Toxicity
possibility of generating content (whether it be text, images, or other modalities) that is offensive, disturbing, or otherwise inappropriate
Hallucinations
assertions or claims that sound plausible but are verifiably incorrect.
Intellectual Property
Protecting intellectual property was a problem with early LLMs. This was because the LLMs had a tendency to occasionally produce text or code passages that were verbatim of parts of their training data, resulting in privacy and other concerns
Plagiarism and Cheating
Disruptions of the nature of work
Hyperparameters
Settings that define the model structure and learning algo and process
Set before training begins
e.g.: learning rate, batch size, number of epochs
Important Hyperparameters
1. Learning rate
2. Batch size
3. Number of epochs
Inferencing – when a model is making prediction on new data
Real time, batch
inferencing at edge – Small LM on edge device, very low latency, low compute footprint, close to where data is
LLM on remote server
Core Dimensions of responsible AI
The core dimensions of responsible AI include fairness, explainability, privacy and security, robustness, governance, transparency, safety, and controllability.
Explainability
Humans must understand how models are making decisions and address any issues of bias, trust, or fairness. Explainability empowers users to verify system functionality, check for unwanted biases, increase useful human control, and place appropriate trust in AI systems. This dimension of AI promotes the responsible development and deployment of AI technology for the benefit of society. Without explainability, AI could lose public trust because of inscrutable failures.
Privacy and Security
at a privacy level, individuals control when and if their data can be used. At the security level, it verifies that no unauthorized systems or unauthorized users will have access to the individual’s data.
Transparency communicates information about an AI system so stakeholders can make informed choices about their use of the system
Veracity and robustness in AI refers to the mechanisms to ensure an AI system operates reliably, even with unexpected situations, uncertainty, and errors. models that are resilient to changes in input parameters, data distributions, and external circumstances.
Governance is a set of processes that are used to define, implement, and enforce responsible AI practices within an organization.
Business Benefits of Responsible AI
Increased trust and reputation
Regulatory Compliance
Mitigating Risks: Responsible AI practices help mitigate risks such as bias, privacy violations, security breaches, and unintended negative impacts on society. This reduces legal liabilities and financial costs.
Competitive advantage
Improved decision making
Improved products and business
Amazon Services and tools for Responsible AI
Amazon SageMaker
fully managed ML service
build, train and deploy ML models in production
You can store and share data without having to build and manage your own servers
provides managed ML algorithm
supports bring your own algo and frameworks
Amazon Bedrock
makes available high-performing FMs from AI startups and amazon for your use through unified API
You can customize FMs with your own data and securely integrate and deploy this into your applications
Reviewing Amazon service tools for responsible AI
FM Evaluation
safeguards for generative AI
bias detection
model prediction explanation
monitoring and human reviews
governance improvement
Foundation model evaluation
evaluate a FM to determine if it will be suited for your specific use case
Model evaluation on Bedrock and Sagemaker clarify:
You can evaluate, compare and select the best FM for your use case in just a few clicks.
Automatic Evaluation:
offers predefined metrics, such as accuracy, robustness and toxicity
Human Evaluation:
offers subjective or custom metrics, such as friendliness, style and alignment to brand voice. You can use in house employee or AWS managed team as reviewer.
Amazon Sagemaker
Fully managed service for developers/data scientists to build ML models.
Typically difficult to do all the processes in one place and provision servers as well. Sagemaker does it for you.
Collect and prepare data
Build and train ML models
Deploy the models and monitor the performance of the predictions
SageMaker – Built in Algorithms
Supervised Algorithms
– Linear regressions and classifications
– KNN Algorithms (for classification)
Unsupervised Algorithms
– Principal Component Analysis (PCA)
– K-means – find grouping within data
– Anamoly detection
Textual Algorithms
– NLP, Summarization
Image Processing
– classification, detection
Sagemaker – Automatic Model Tuning (AMT)
Try different parameters and see if you get better performance out of it.
Sagemaker does it for you automatically
Define the objective metric, i.e. what we want to optimize for
AMT automatically chooses hyperparameter ranges, search strategy, maximum runtime of a tuning job and early stop condition
Helps you save time and money
Sagemaker – Model deployment and Inference
Deploy with one click, automatic scaling, no servers to manage
Real Time – One prediction at a time, upto 6 MB payload, 60 seconds processing time
Serverless – Uses lambda, Idle period between traffic spikes, you specify the memory configuration, cold start, upto 6 MB payload, 60 seconds processing time
Asynchronous – For large payload size upto 1 GB, long processing times , request and response are in Amazon S3, near real time latency requirements, Max 1 hour processing time
Self managed – you can deploy on ECS, EKS, Lambda, EC2
Batch – prediction for an entire dataset, request and response in S3. OK to wait for the result. Large datasets, GB in size
Sagemaker Studio
End to End ML development from a unified interface
Team collaboration
Tune and debug ML models
Deploy ML models
Automated workflows
Sagemaker – Data wrangler
Prepare tabular and image data for machine learning
Data preparation, transformation and feature engineering
Single interface for data selection, cleansing, exploration, visualization and processing
SQL Support
Data quality tool
What are ML Features
Features are inputs to ML models used during training and used for inference
e.g. music dataset: song rating, listening duration, and listener demographics
customer id, name, birthdate => customer id, name, age
Important to have high quality features across your datasets in your company for reuse
Sagemaker – feature store
You have feature store in sagemaker, where you can ingest data from a variety of sources
you can transform the data into feature from within feature store
can also publish from data wrangler to featurestore
You company has access to this feature store and can be reused
Also discovered with sagemaker studio
Sagemaker clarify
Evaluate foundation models
Leverage an AWS managed team or bring your own employees
Use built in datasets or bring your own datasets
Built in metrics and algorithms
Part of sagemaker studio
Clarify – Modeal explanibility
A set of tools to help explain how ML models make predictions
Debug predictions provided by the model after it’s deployed
Helps increase the trust and understanding of the model
e.g.: Why did the model predict a negative outcome?
Clarify – Detect Bias
Ability to detect and explain biases in your dataset and models
measures bias using statistical metrics
specify input features and bias will be automatically detected
e.g. a group that is more represented, wrong proportions
Sagemaker Ground Truth
RLHF – Reinforcement Learning from Human Feedback
model review, customization and evaluation
align model human preferences
learning where human feedback is included in the “reward” function
Human feedback for ML
creating or evaluating your model
Data generation or annotation
Reviewers: Amazon workers, your employees or third party vendors
SageMaker Ground Truth Plus: Label Data
SageMaker – ML Governance
Model cards – essential model information
example: intended uses, risk ratings and training details
Model dashboard: centralized repository for all your models, you get information and insights for all your models
Role Manager: define roles for personas, e.g. data scientist, MlOps engineer
Centralized portal where you can view, search and explore all of your models
e.g. track which models are deployed for inference
Helps you find models that violate thresholds you set for data quality, model quality, bias and lets you take prompt action
SageMaker model Monitor
Monitor the quality of your model in production: continuous or on-schedule
Alerts for deviation in model quality: fix data or retrain model
e.g. loan model starts giving loans to people who don’t have correct credit score
SageMaker model registry
Centralized repo that allows you to track, manage and version ML models
Lets manage model by approval status, automate deployment, sharing models
Orchestration options:
Amazon sagemaker pipelines
Amazon managed workflows for apache Airflow
AWS Step functions
Third party orchestration
SageMaker pipelines
workflow that automates the process of building, training and deploying a ML model
CI/CD service for ML
helps you build, train, test and deploy 100s of models automatically
Supported step types:
Processing – for data processing
Training – for training a model
Tuning – for hyperparameter tuning
AutoML – to automatically train a model
Model – to create or register a sagemaker model
ClarifyCheck – perform drift checks against baselines (Data bias, model bias, model explainability)
QualityCheck – perform drift checks against baseline (Data quality, model quality)
SageMaker JumpStart
ML hib to find pre-trained FM, computer vision models or NLP
Large collection of models from Hugging Face, DataBricks
Models can be fully customized for your data and use case
Deployed on sagemaked directly
Pre-built ML solutions
Sagemaker Canvas
Visual interface for building ML model, no coding required
Access to ready to use models, jumpstart or bedrock
Build your own custom model using AutoML powered by SageMaker Autopilot
Part of Sagemaker studio
Leverage Data Wrangler for data preparation
It has ready to use models from Amazon Rekognition, Comrehend and Textract
MLFlow on Sagemaker
an open source tool which helps ML teams manage the entire ML lifecycle
From sagemaker you can launch MLFlow Tracking Servers, which is a server that runs MLFlow software.
Used to track runs and experiments
Fully integrated with Sagemaker, part of SageMaker studio
AI Challenges and Responsibilities
Responsible AI
Making sure AI systems are transparent and trustworthy
Mitigating potential risk and negative outcomes
Throughout the AI lifecycle: design, dev, deploy, monitor and evaluate
Security
Ensure that confidentiality, integrity and availability are maintained
On organizational data and information assets and infrastructure
Governance
Ensure to add value and manage risk in the operation of the business
Clear policies, guidelines and oversight mechanisms to ensure AI systems align with legal and regulatory requirements
Improve trust
Compliance
Ensure adherence to regulations and guidelines
Sensitive domains such as healthcare, finance, legal applications
Core dimensions of responsible AI
Fairness: promote inclusion and prevent discrimination
Explainability
Privacy and security: Individuals control when and if their data is used
Transparency
Veracity and robustness: reliable even in unexpected situation
Governance: define, implement and enforce responsible AI practices
Safety: algo are safe and beneficial for individuals and society
Controllability: ability to align human values and intent
Responsible AI – AWS services
Amazon Bedrock: human or automatic model evaluation
Guardrails for Amazon bedrock:
Filter content, redact PII, enhanced safety and privacy
Block undesired topics
Filter harmful content
Sagemaker Clarify
FM evaluation on accuracy, robustness, toxicity
Bias detection (Ex: data skewed towards middle aged people)
Sagemaker Data Wrangler
fix bias by balancing dataset
e.g. Augment the data (generate new instances of the data)
Sagemaker model monitor: quality analysis in production
Amazon Augmented AI (A2I): human review of ML predictions
Governance: Sagemaker Role Manager, Model Cards, Model Dashboard
AWS AI service cards
Amazon Texttract and Rekognition has it
Form of responsible AI documentation
Help understand the service and its features
Find intended use case and limitation
Responsible AI design choices
deployment and performance optimization best practise
Interpretability
The degree to which a human can understand the cause of a decision
Access into the system so that a human can interpret the model’s output
Answer Why and How
Explainability
Understand the nature and behavior of the model
Being able to look at inputs and outputs and explain without understanding exactly how the model came to the conclusion. Based on the input and output, I can probably explain how it reached here.
It can sometimes be enough
High Interpretability – Decision Trees
Supervised learning algorithm used for Classification and Regression tasks
Splits data into branches based on feature values
Splitting can be simple rules such as “is the feature greater than 5”
Although it might require complex algorithm but it is easily readable and interpretable
Prone to overfitting if you have too many branches, as you are fitting all your data into most amount of critirea
Easy to interpret and clear visual representation
Partial Dependence Plots (PDP)
Show how a single feature can influence the predicted outcome, while holding other features constant
Particularly helpful when the model is black box
Helps with interpretability and explainability
Human Centered design for explainable AI
Approach to design AI systems with priorities for human’s needs
1. Design for amplifies decision making
Minimize risk and errors in a stressful or high-pressure environment
Design for clarity, simplicity, usability
Design for reflexivity (reflect on decision making process) and accountability
2. design for unbiased decision-making
Decision process is free from bias
Train decision-makers to recognize and mitigate biases
3. Design for human and AI learning
Cognitive apprenticeship: AI systems learn from human instructors and experts
Personalization: meet the specific needs and preference of a human learner
User-centered design: accessible to a wide range of users
Gen AI Capabilities and Challenges
Capabilities of Gen AI
Adaptability
Responsiveness
Simplicity
Creativity and exploration
Data efficiency
Personalization
Scalibility
Challenges of gen AI
Regulatory violations
Social Risks
Data security and privacy concerns
Toxicity
Hallucinations
Interpretability
Nondeterminism
Plagiarism and Cheating
Toxicity
Generating content that is offensive, disturbing or inappropriate
Defining what constitutes “toxicity can be a challenge
Boundary between restricting toxic content and censorship
What about quotations of someone that can considered toxic? Should they be included?
Mitigation:
Curate the training data by identifying and removing offensive phrases in advance
Use guardrail models to detect and filter our unwanted content
Hallucinations
Assertions or claims that sound true but are incorrect
due to next-word probability sampling employed by LLM
Mitigation:
Educate users that content generated by the model must be checked
Ensure verification of content with independent sources
Mark generated content as unverified to alert users that verification is necessary
Plagiarism and cheating
Worries that Gen AI can be used to write college essays, writing samples for job applications
Debate going on
difficult to trace the source
Prompt misuse
Poisoning:
Intentional introduction of malicious or biased data into the training data set of the model
leads to the model producing biased, offensive, or harmful outputs
Hijacking and Prompt Injection:
Influencing the outputs by embedding specific instructions within the prompts themselves
Hijack the model’s behavior and make it produce outputs that align with the attacker’s intentions
Exposure:
The risk of exposing sensitive or confidential information to a model during training or inference
Prompt leaking
The unintentional disclosure or leakage of the prompts or inputs used with a model
It can expose protected data or other data used by the model, such as how the model works
Jailbreaking
circumvent the constraint and safety measures implemented in a gen model to gain unauthorized access or functionality
Few-shot jailbreaking and many-show jailbreaking. Many-shot means asks a lot of prompts and model will give in
Compliance for AI
Some industries would require extra level of compliance, such as finance, aerospace, healthcare
e.g. Reporting regularly to federal agencies, or if you have regulated outcomes, such as mortgage and credit applications
AI standard compliance challenge
Complexity and Opacity: Challenging to audit how systems make decisions
Dynamism and Adaptability: AI systems change over time, not static
Emergent Capabilities: Unintended capabilities a system may have
Unique risks: Algorithmic bias, privacy violations, misinformation
Algorithm accountability: Should be transparent and explainable. promotes fairness, non-discrimination and human rights
Model cards
Standardized format for documenting key details about an ML model
Can include source citations and data origin documentation
Details about the datasets used, their sources, licenses and any known biases.
Intended use, risk rating of a model
Helpful to support audit activities
e.g. AWS AI Service Cards
Governance for AI
Managing. optimizing and scaling the organizational AI initiative
Instrumental to build trust
Mitigate risks, such as bias, privacy violations
Aligned with legal and regulatory requirements
Protect form legal and reputational risk
Governance framework
Establish an AI governance board or committee: rep from legal, compliance, data, SME
Define roles and responsibilities: such as oversight, policy-making, risk assessment
Implement policies and procedure – develop comprehensive policies and procedure that address the entire AI lifecycle from data management to model deployment and monitoring
Governance strategies
Policies: principles, guidelines and responsible AI considerations
Review Cadence – combination of technical, legal and responsible AI review
Review Strategies – Technical reviews on model performance, data quality, algorithm robustness
Transparency Standards
Team training requirements on relevent policies, guidelines and best practices
Responsible AI : frmaework and guidelines
Governance structure and roles: establish a committee
Data sharing and collaboration
Data lifecycles
Data logging
Data residency
Data monitoring
Data analysis
Data retention
Data Lineage: Source citation, databases, datasets used
Document data origin
Cataloging – organization and documentation of datasets
Security and Privacy for AI systems
Threat detection
fake content, manipuklated data
deploy AI based threat detection
Vulnerability managemnt
Identify vulnerabilies in AI systems
patch management and update process
Infrastructure protection
Secure the cloud computing platform
Access control
Ensure you can withstand systems failures
Prompt Injection
Implement guardrails, such as prompt filtering, sanitization, validation
manipulated input prompts
Data Encryption
Encrypt data at rest and in transit
manage encryption keys properly
Monitoring AI systems
Performance Metrics
Model accuracy – ratio of positive predictions
Precision – ratio of true positive predictions
Recall – ratio of true positive predictions compare to actual positive
F1-score – average of precision and recall (good balance measured)
Latency – time taken by the model to make a prediction
Infrastructure monitoring (Catch bottlenecks and failures)
Compute resources
Networking
Storage
AWS Shared responsibility model
AWS – security of cloud and managed service
You – Security in the cloud, data mgmt, access control, encrypting application data, etc
Shared control – patch management, configuration mgmt
Secure Data Engineering – Best practices
Assessing Data quality
Completeness, accuracy, timeliness, consistency
Privacy-enhancing technologies
Data masking, data obfuscation to minimize risk of data breaches
Encryption, tokenization to protect data during processing and usage
Data Access Control
role based access control, fine grained permission
single sign on
monitor and log all data access activities
Data integrity
Data is complete, consistent and free from error and inconsistencies
data backup and recover strategy
maintain data lineage and audit trails
Gen AI security scoping matrix
Framework designed to identify and manage security risks associated with deploying GenAI applications
5 defined GenAI scopes from low to high
1. Consumer App – uses public genai services, e.g. chatgpt, very low ownership
2. Enterprise App – uses an app or saas with genai features, e.g. salesforce, high ownership
3. Pre-trained model – building your app on a versioned model, e.g. bedrock base model, medium ownership
4. fine-tuned models – fine tuning a model on your data, e.g. bedrock customized models, high ownership
5. self-trained model – train model from scratch, sagemaker, high ownership
Security Generative AI
Governance & Compliance
Legal & Privacy
Risk Management
Controls
Resilience
MLOPS
Make sure models aren’t just developed, but also deployed, monitored, retrained systematically and repeatedly
Key Principles: Version Control, Automation, CI, CD, C Retraining, C Monitoring
Amazon BedRock and GenAi
GenAI – subset of deep learning. Used to generate new data that is similar to the data it was trained on.
It can be trained on Text, Image, Audio, Code, Video
Pretrain foundation model. It adapts and can do text generation, summarization, extraction, chatbot, question answering
Foundation Model
To generate data, we must rely on a foundational model
They are trained a wide variety of input data
It may cost tens of millions of dollar to train
e.g. GPT-4o is FM for ChatGPT. others include from OpenAI, Meta, Amazon, Google
LLMs
designed to generate coherent human like text
Trained on large corpus of data. Books, articles, website data
can perform language related tasks
We interact with LLM by prompt.. e.g. what is AWS
Model will leverage all the existing content it has learned from to generate new content
It is non-deterministic – not same answer for same questions for different user
Why is it non-deterministic:
LLM generates a list of potential words alongside probabilities
GenAI for images.. it can generate images from text and images as well.
Training: Forward diffusion process: Picture to noise
Generating: Reverse diffusion: Noise to image
Amazon BedRock
Build GenAI applications on AWS
Keep control of your data used to train the model
pay-per-use
unified APIs – Same for all your models
leverage a wide variety of foundation models
out of the box features: RAG, LLM agents
Security, Privacy, Governance and Responsible AI features
Bedrock makes a copy of the FM and keeps it in your account. You can further fine tune the model with your data
None of you data is used to train the FM with the provider
Interactive playground: ask questions to the prompt
Knowledge Base (RAG) – access to external data sources fetching more relevant and accurate responses
Fine tune – update the model with our data
Multi-modal Models
Does NOT rely on a single type od input (text, images or audio only)
Does NOT create a single type of output
How to choose base foundation model:
Model types, performance requirements, constraints, compliance, model size, licensing agreement, context windows, latency
Multimodal models – varied type of input and output
Amazon Titan – High performing foundation models from AWS
Image, text, multimodal model choices via a fully-managed APIs
can be customized with your own data
Fine tuning a model
Adapt a copy of a foundation model with your own data
It will change the weight of the base foundation model
Training data must: adhere to a specific format and be stored in amazon s3
You must use “Provisioned Throughput” to use a fine tuned model
Instruction based fine tuning
improved performance of pre-trained FM on domain-specific tasks
= further trained on a particular field or area of knowledge
uses labeled examples that are prompt-response pairs
Continued Pre-training
Provide unlabeled data to continue the training of an FM
also called domain adaptation fine tuning
Good to feed industry specific terminology into a model
Can continue to train the model as more data becomes available
Single-Turn messaging
Part of instruction based fine tuning
system: context of the conversation
messages: an array of message objects, each contaning a role and content, Role is either user or assistant, content is text content of the message
Multi-turn Mesaging
provide instruction based fine tuning for a conversation
Re-training a FM requires a higher budget
Instruction based fine tuning is usually cheaper as computations are less intense and amount of data required is less
You must prepare the data, fine tune and evaluate the model
Running fine tune is also expensive, as it needs provisioned throughput
Transfer Learning
re-using a pre-trained model to adapt it to a new related task
Widely used for image classification
fine tuning is a specific kind of transfer learning
Fine tuning use cases:
up-to-data information
exclusive data
targeted use case
Bedrock – Evaluating a model
Automatic Evaluation
Evaluate a model for quality control— select a model, select a task type (text summarization), own prompt dataset or use build in, scores are calculated automatically
Benchmark Dataset:
curated collection of data designed specifically at evaluating the performance of language models
wide range of topics
Helpful to measure accuracy, speed and efficiency, scalability
Some benchmarks datasets allow you to very quickly detect any kind of bias and potential discrimination against a group of people
Humans can also be used to evaluate
thumbs up/down, ranking
Automated metrics to evaluate an FM
Rouge: evaluate automatic summarization and machine translations system
Rouge-N – matching n-grams between ref and generated text
Rouge-L – longest common subsequence
BLEU – evaluate the quality of generated text, especially for translations
BERTScore: semantic similarity between generated text
use pre-trained BERT model
Perplexity: How well the model predicts the next token (lower is better)
Business Metrics to evaluate FM
User satisfaction
Average revenue per user
Cross-Domain performance
Conversion rate – generate recommended desired outcomes
Efficiency – in computation, resource utilization
Amazon Bedrock – RAG n knowledge base
RAG – Retrieval Augmented Generation
Allows a foundation model to reference a data source outside of its training data.
Prompt goes to knowledge base which is maintained by bedrock. Knowledge base is backed by vector database.
Bedrock allows us to choose database of our choice, and creates Vector Embeddings
retrieves relevant information from vector DB and passed to foundation model along with the query
After which foundation model generates the response
Retrieval – we retrieve the data outside of foundation model
Augment – we augment the prompt with the external data
Opensearch service, amazon aurora – vector database
Embedding model – how to convert data into vector – titan or cohere
RAG Vector Databases – Types
- Amazon OpenSearch service – search and analytics database
real time similarity queries
store millions of vector embeddings
scalable index management
fast nearest-neighbor (kNN) search capability
2. Amazon DocumentDB – With MongoDB compatibility – NoSQL database
real time similarity queries
store millions of vector embeddings
3. Amazon Aurora – relational database, proprietory on AWS
4. Amazon RDS for postgreSQL – relational database, open-source
5. Amazon Neptune – graph database
RAG data sources
Amazon S3
Confluence
Sharepoint
Salesforce
Web pages
RAG Use cases
Customer Service chatbot
Legal research and analysis
healthcare question answering
GenAI concepts – Tokenization
Tokenization: converting raw text into a sequence of tokens
word-based
subword
Context Window
the number of tokens an LLM can consider when generating text
Larger the window, more information and coherence
Large context require more memory and processing power
thus, first factor to look at when considering a model
Embeddings
create vector (Arrays of numerical value) out of text, images or audio
e.g. cat – 0.025, -0.009, -0.011, 0.021
Vectors have high dimensionality to capture many features for one input token, such as semantic meaning, syntactic role, sentiment
Embedding models can power search applications
words that have a semantic relationship have similar encoding
dimensionality reduction of word embedding to 2D
Color visualization of vectors embedding.
Bedrock – Guardrails
Control the interaction between users and foundation models
Filter undesirable and harmful content
e.g. guardrail setup to block food recipe.. therefore, when someone asks for “something to cook tonight”, the it will say it is restricted
Bedrock – Agents
Manage and carry out various multi-step tasks related to infrastructure provisioning, application deployment and operational activities.
Task Coordination: perform tasks in the correct order and ensure information is passed correctly between tasks
Agents are configured to perform specific pre-defined action groups
Integrate with other systems, services, DB and API to exchange data or initiate actions
Leverage RAG to retrieve information when necessary
Agents can interact with API or lambda or even knowledge base
Bedrock – Cloudwatch Integration
model invocation logging
build alerting
CW metrics
Bedrock studio – give access to Amazon Bedrock to your team so they can easily create AI-powered applications
Watermark detection – check if an image was generated by Amazon Titan generator
Pricing:
1. On demand
pay as you go.
Text, Embedding, IMage models
Works with base models only
Batch
multiple predictions at a time
Can provide discount upto 50%
Provisioned Throughput
purchase model units for a certain time
Throughput – max number of input/output tokens processed per minute
Works with base, fine tune and custom models
Model improvement techniques cost order
- Prompt Engineering
No model training needed (no additional computation or fine-tuning) - RAG
uses external knowledge (FM does not need to know everything, less complex)
No FM changes - Instruction based fine tuning
FM is fine-tuned with specific instructions (requires additional computation) - Domain Adaptation fine-tuning
Model is trained on a domain-specific dataset (requires intensive computation)
Bedrock – Cost savings
- On-demand – great for unpredictable workloads
- Batch – 50% discount
- Provisioned throughput – not a cost-saving measure, great to reserve capacity
- Temperature, Top K, Top P – no impact on pricing
- Model size – ususally a smaller model will be cheaper, varies based on providers
- number of input and output tokens – main driver of cost
Prompt Engineering
Prompt gives little guidance and leaves a lot to the model’s interpretation
Prompt Engineering = developing, designing and optimizing prompts to enhance the output of FMs for your needs
Improved prompting technique consists of:
Instructions – a task for the model to do (description, how the model should perform)
Context – external information to guide the model
Input Data – the input for which you want a response
Output Indicator – the output type or format
Negative Prompting
A technique where you explicitly instruct the model on what not to include or do in its response
Negative prompting helps to:
Avoid unwanted content – explicitly states what not to include, reducing the chances of irrelevant or inappropriate content
Maintain focus – helps the model stay on topic and not to stray into areas that are not useful or desired
Enhance clarity – prevents the use of complex terminology or detailed data, making the output clearer and more accessible
Prompt performance optimization
System prompts – how the model should behave and reply
Temperature (0 to 1) – creativity of the model’s output
Low (ex: 0.2) – outputs are more conservative, repetitive, focused on most likely response
High(ex: 1.0) – outputs are more diverse, creative and unpredictable, maybe less coherent
Top P (0 to 1)
Low P (ex: 0.25) – consider the 25% most likely words, will make a coherent response
High P (ex: 0.99) – consider a broad range of possible words, possibly more creative and diverse output
Top k – limits the number of probable words
Low K (ex: 10) – more coherent response, less probable words
High K(ex: 500) – more probable words, more diverse and creative
Length – maximum length of the answer
Stop Sequences – tokens that signal the model to stop generating output
Prompt Latency
Latency is how fast the model responds
It’s impacted by few parameters:
The model size
model type
number of tokens in the input
number of tokens in the output
Latency is not impacted by Top P, Top K, Temperature
Prompt Engineering Techniques
Zero-shot prompting: present a task to the model without providing examples or explicit training for that specific task
You fully rely on the model’s general knowledge
The larger and more capable the FM, the more likely you’ll get good results
e.g. “write a short story about a dog”
Few-shots prompting
provide examples of a task to the model to guide its output
If you provide one example only, it is called one-shot or single shot
here are two short stories.. Write a short story … ”
Chain of thought prompting
Divide a task into a sequence of reasoning steps, leading to more structure and coherence
Using a sentence like “Think step by step” helps
Helpful when solving a problem as a human usually required several steps
Can be combined with zero-shot or few-shots
RAG
Combine the model’s capability with external data sources to generate a more informed and contextually rich response
The initial prompt is then augmented with external information
Prompt Template
Simplify and standardize the process of generating prompts
“”” {text} {question}”””
Helps with:
Processes user input text and output prompts from foundation models
Orchestrate between the FM, action groups and knowledge bases
formats and returns the responses to the user
You can also provide examples with few-shots prompting to improve the model performance
These can be used with bedrock agents as well
Prompt Template injections
“Ignoring the prompt template attack”
Users could try to enter malicious inputs to hijack our prompt and provide information on a prohibited or harmful topic.
Add explicit instructions to ignore any unrelated or potential malicious content.
e.g. you can insert: “the assistant must strictly adhere to the context of the question and should not respond to any unrelated context
Amazon Q
Fully managed Gen-AI assistant for your employees
Based on your company’s knowledge and data
Answer questions, provide summaries, generate content, automate tasks
Perform routine actions, e.g. submit time-off requests, send meeting invites
Built on Amazon bedrock (but you can’t choose the underlying FM)
What you can ask Amazon Q business
– Write a job posting for a senior product manager role
– Create a social media post under 50 words
– what was discussed duting meeting of week 4/12
Data Connectors
connects to 40+ popular enterprise data sources
Amazon S3, RDS, Aurora…
Once connection is made, it will crawl these sources and get the data, allow you to search and query them
Plugins
Allows you to interact with 3rd party services, like JIRA, ServiceNow….
Can create custom plugins as well
Amazon Q Business + IAM identity center
Users can be authenticated through IAM identity center
Users receive responses generated only from the documents they have access to
IAM identity center can be configured with external identity providers
– IdP: Google, MSAD
Amazon Q Business – Admin controls
Controls and customize responses to your organizational needs
Admin control == guardrails
Block specific words or topics
Respond only with internal information or/and can use external knowledge
Global controls n topic level controls
Amazon Q Apps
Create Gen AI-powered apps without coding by using natural language
Leverages your company’s internal data
Possibility to leverage plugins (Jira, etc)
Amazon Q Developer
Answer questions about the AWS documentation and AWS service selection
Answer questions about resources in your AWS account
Suggest cli commands to run to make changes to your account
Helps you do bill analysis, resolve errors, troubleshooting
e.g. what were the top three highest-cost services in QA
AI Code companion to help you code new applications (Similar to GitHub copilot)
Supports many languages: Java, Python…
Real time code suggestions and security scans
Software agent to implement features, generate documentation, bootstrapping new projects
Integrates with IDE
PartyRock
GenAI app-building playground. Powered by Amazon bedrock
Can be accessed even if you don’t have an AWS account
For a curated list of Extensive Interview Questions click here